なんでもAIに聞ける時代に、「自社しか知らない顧客の事実集」を構築すべき理由
- プロダクトマネジメント
- 経営
- 組織

2022年11月にChatGPTが登場して以降、誰もが簡単に情報を引き出せる時代が到来しました。
これまで、何時間もかけて調べ資料にまとめていたものが、場合によってはほんの数分でまとまることもあります。
「AIに聞けば、(ネット上に出ている情報は)なんでも出てくる」ようになった今、ますます「自社しか知らないユーザーの事実 = インサイトセンター」の必要性が高まっています。
本ドキュメントでは、業務に生成AIを取り入れている・取り入れようとしているチームにとって、差がつく「インサイトセンターへの投資」について解説します。
生成AIの2つの限界
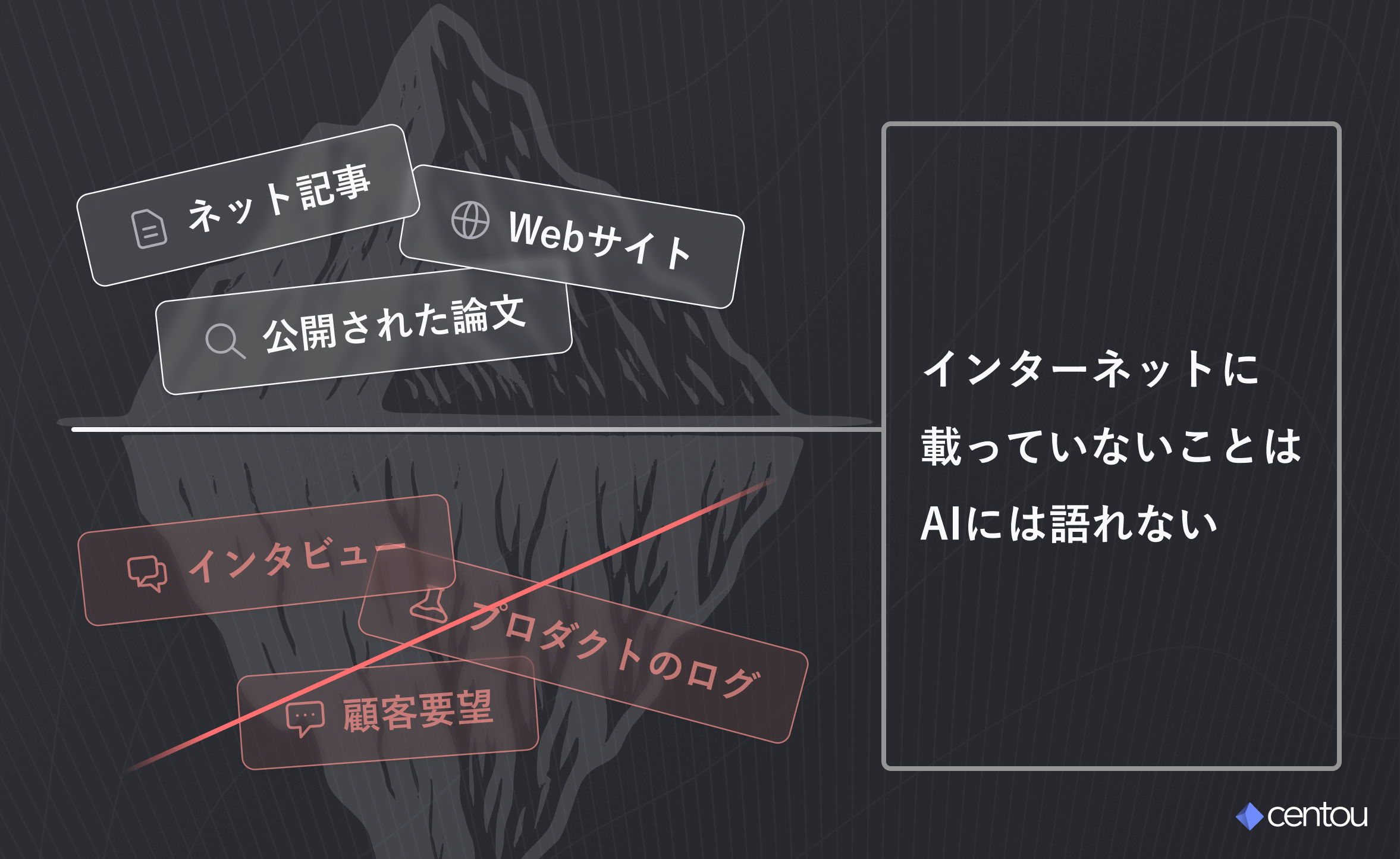
ChatGPTをはじめとする生成AIは、大規模な言語モデル(LLM)によって動いています。これらのモデルが学習する情報は、基本的にはインターネット上の公開データやライセンスされた情報です。
逆に、以下のような非公開の一次情報は、ほとんどの生成AIの中には含まれていません。
- 自社のカスタマーサポートに届いた声
- ユーザーインタビューで得られた事実
- 自社プロダクトのログにしか現れない利用行動
つまり、「インターネットに載っていないこと」は、AIには語れないのです。
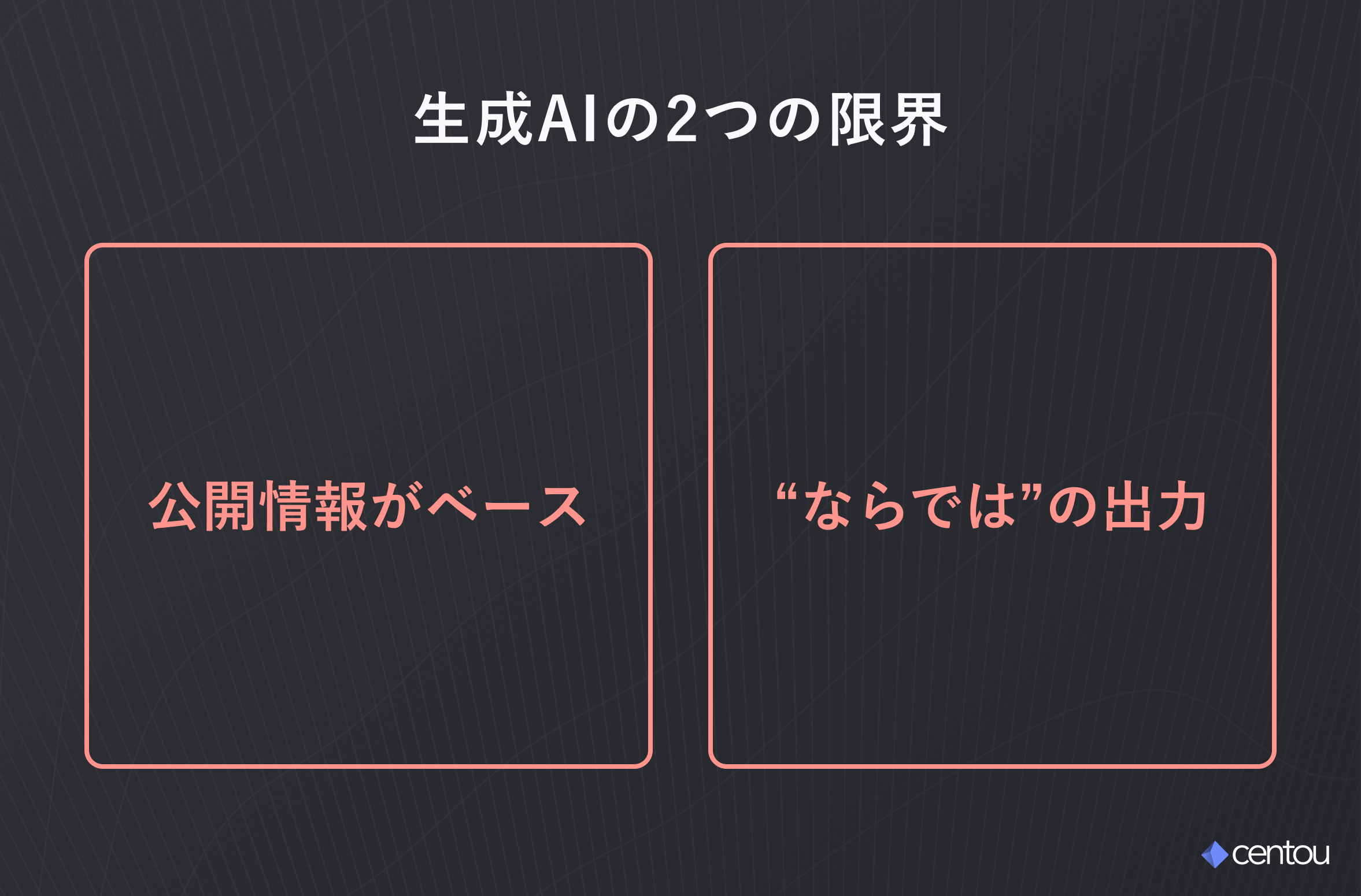
また、上記のようなことから、生成AIによって「60点」(一般的な知識やプラクティス)に到達することは非常に早くなった一方で、以下のような100点ラインに到達するためには限界があります。
- 他でもない、自社 / 自サービスでどのように改善するべきか?
- 自社サービスの顧客の特性や特徴を踏まえた際に、本当に良い施策か?
一般的な生成AIだけでは、自社の顧客や事業のコンテキストに合わせた仮説づくりや回答には限界があるということです。
誰もが使える生成AIだけを使いこなしていても、「すでに世の中に公開されている価値の模倣」にしかならないのです。
価値の模倣だけでは、選ばれる理由の弱いサービス / プロダクトから抜け出すことができないでしょう。
自社しか知らない顧客の事実集 = インサイトセンターの価値
では、「価値の模倣」だけに止まらないようにするためには何が必要なのでしょうか?
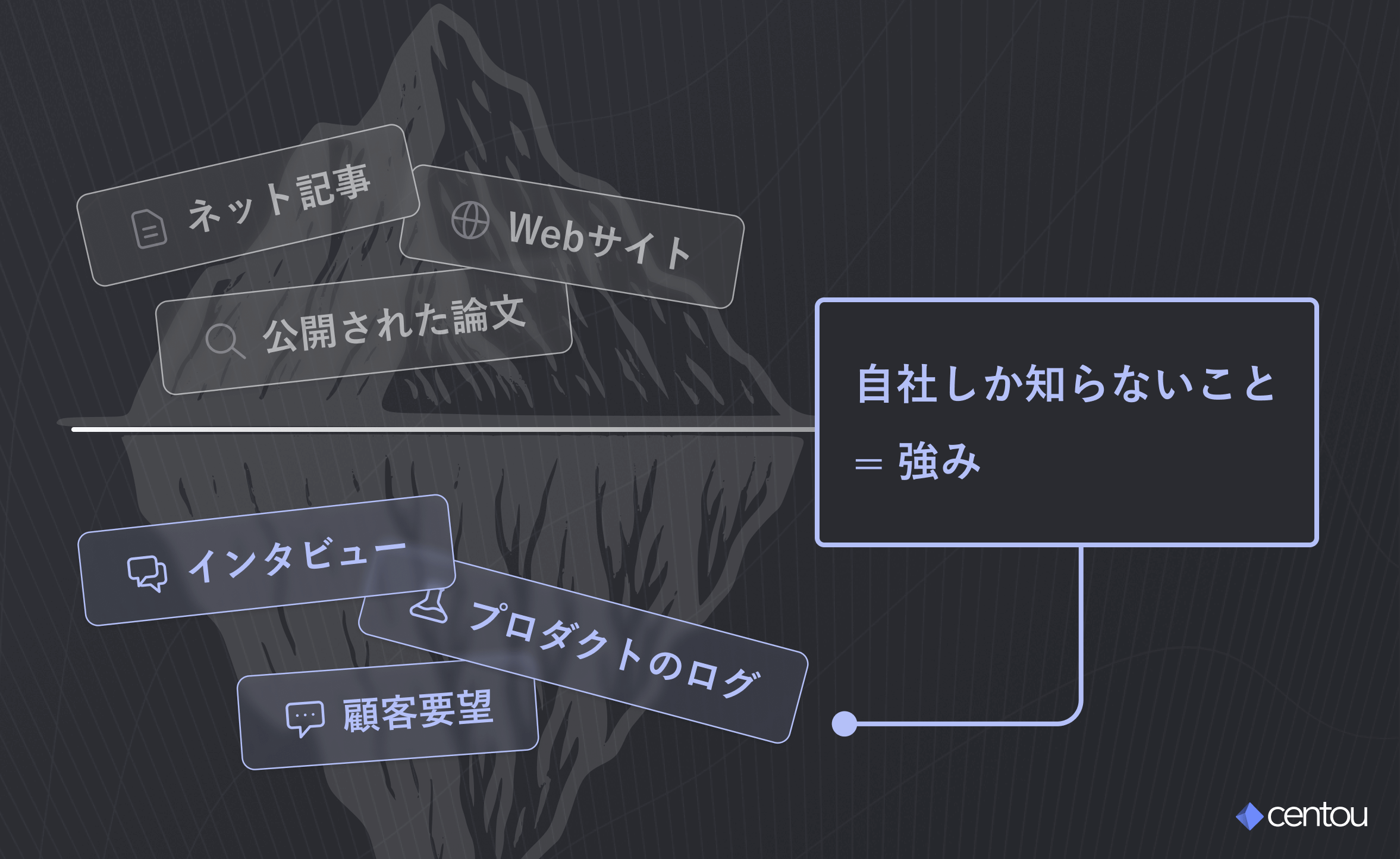
ここに「インサイトセンター(顧客の事実集)」を構築するべき理由があります。
「AIに聞けばなんでも返ってくる」時代において、「自社しか知らないことがある」というのは、大きな強みになります。
IBMが2024年に発表した調査「AI in Action 2024」によれば、AI活用を推進する企業の多くは、独自の企業データを活用して生成AIをカスタマイズし、差別化を図っています。
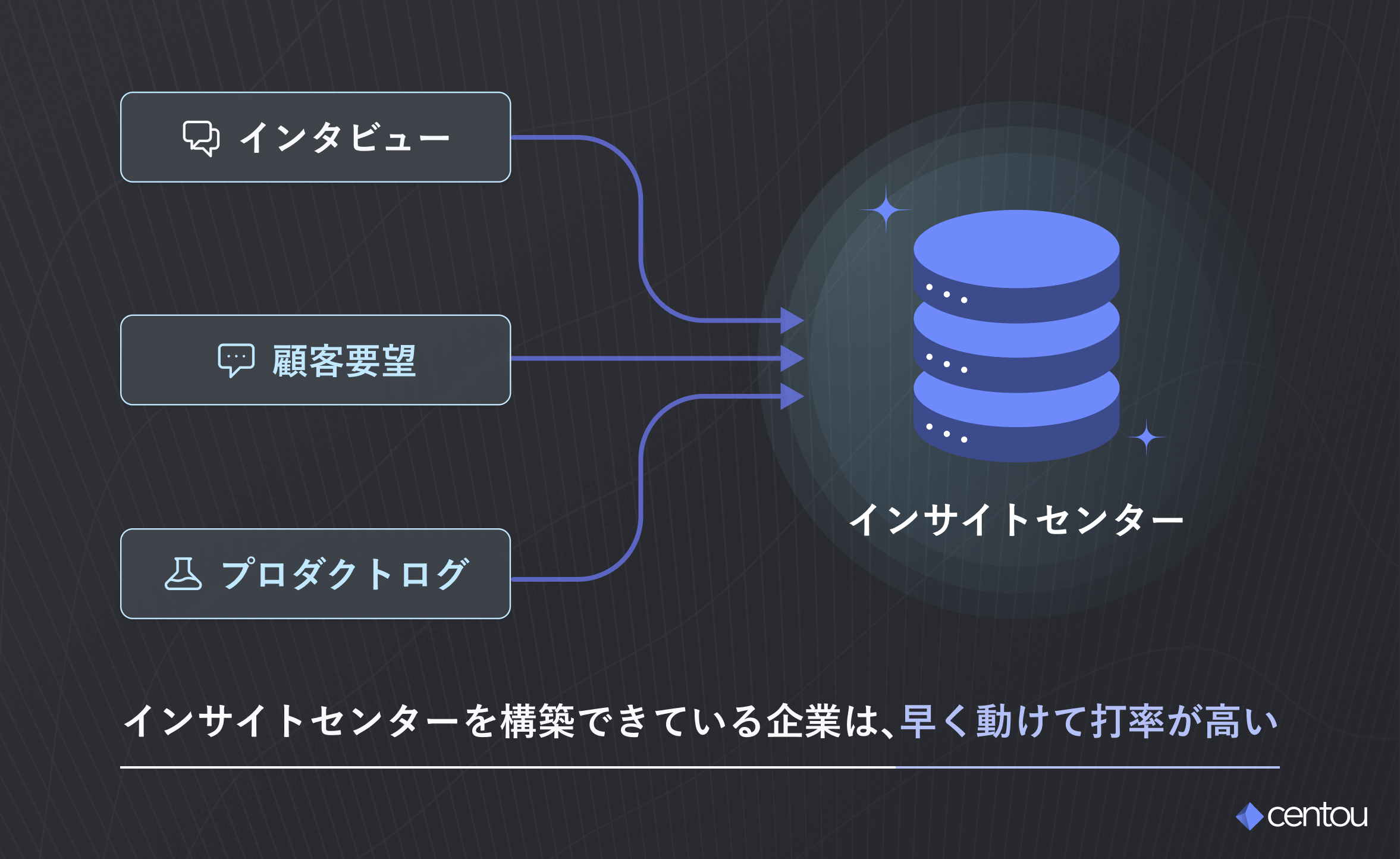
自社しか知らない顧客の事実集 = インサイトセンターがあることによって、多くのメリットを享受することができます。
- 顧客の事実による裏付けが取れるため、社内でのすり合わせや調整のためのミーティングが減り、意思決定が早くなる
- 使われない機能や施策を生まないことで、ムダな人件費や時間を削減できる
- 共通のインプット元があることで、"あの人はあまり筋が良くない..."など、人によるアウトプットのブレが大幅に減る
つまり、インサイトセンターを構築できている企業は、「早く動けて打率が高い」状態になるのです。
想像してみてください。
これまで新しい機能案ができてリリースされるまでに、社内の関係者とミーティングを重ね、過去のデータを漁り、資料にまとめ、またミーティングをする...そうして1機能ができるまでに気づけば数ヶ月...。
インサイトセンターがない企業では、新しい価値を模索することや、その判断に多くの労力を費やします。職種によって目線も違い、チームの士気も下がり、判断も遅くなり、顧客を向いたシャープな初期構想はいつの間にか、角を立たせないための社内のための折衷案になることも...。
しかし、チームで共通のインサイトセンターがあったらどうでしょうか?「どの顧客が何を言っていたか / どう行動していたか」がすぐに辿れて、その場で判断が可能に。
数ヶ月かかってインパクトの小さいリリースをしていた状態から、数週間でシャープな検証ができる状態に。結果として年間で数百万以上の売上インパクトを実現——。
インサイトセンターがあることで、自社ならではの判断・価値提案を、よりすばやく実行できるようになるのです。
インサイトセンターの構築で重要なこと
「インサイトセンター」とは、顧客へのインタビューデータや商談、行動ログなどのあらゆる顧客接点を体系的に収集・整理・活用する仕組みのことです。
難しく考える必要はありません。インサイトセンターは、いわば「顧客の事実をまとめた冷蔵庫」のような存在です。
日々の顧客接点から、事実(食材)を取り出し、分類し、さまざまな形にデータ活用(料理)できるような流れをイメージすると良いでしょう。
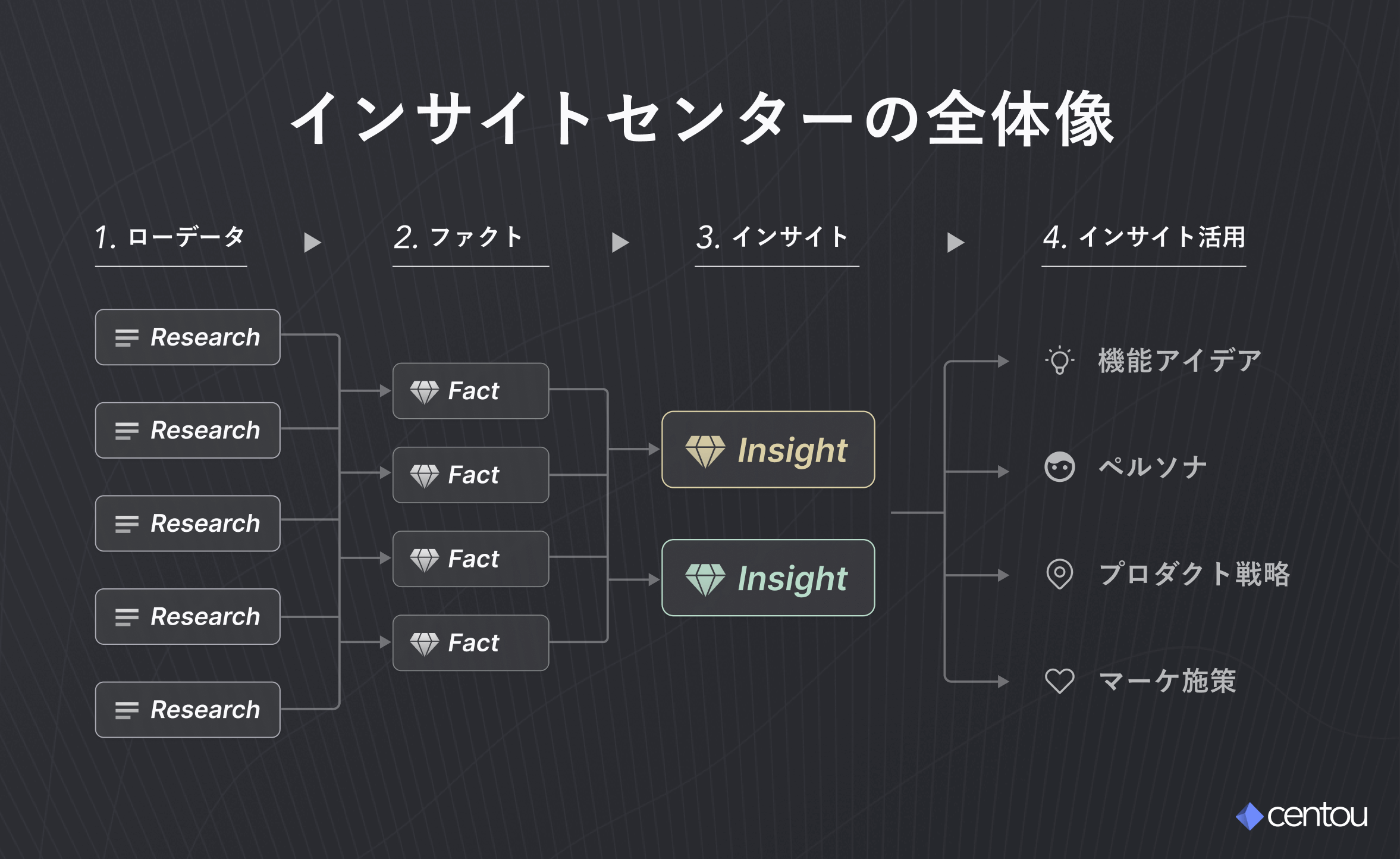
データ構造の設計など、注意すべき点はいくつもありますが、まずはスプレッドシートやNotionなどにラフに蓄積することから始めても良いでしょう。

そして、インサイトセンターの本質は、
- 泥臭いユーザー理解を積み重ねること
- 積み重なったユーザー理解が、共有のインサイトデータとして残されていくこと
の2つです。
泥臭く、熱心に顧客やユーザーとの対話を重ねることが重要です。
この泥臭さこそが、競争優位性につながります。泥臭いユーザー理解の積み重ねは、簡単にはマネできません。

生成AI時代のユーザー理解こそ泥臭く、「泥臭い方がカッコイイ」と捉えるべきでしょう。
小さく始めるインサイトセンター
インサイトセンターは、組織にとっての「攻めの意思決定インフラ」です。
うまく機能すれば強力なパワーを発揮する一方で、これまでインサイト起点の意思決定をしてこなかった組織にとっては、変革の痛みを必要とします。
これまで冷蔵庫を使って生活をしておらず、都度近所のスーパーに買い物に行っていた家族が、冷蔵庫に食材を貯めて取り出すように習慣が変わるのは、容易ではありません。
だからこそ、インサイトセンターは小さく始めるべきでしょう。

- 種まき期
- 小さい実績づくり期
- 浸透期
- 拡大期
浸透を急いで「誰も使わない冷蔵庫」を生み出してしまう企業も少なくありません。まるでオセロのように「インサイト起点の意思決定」を徐々に増やしていくようなイメージで、少しずつ変化を推し進めていくことが実は近道です。
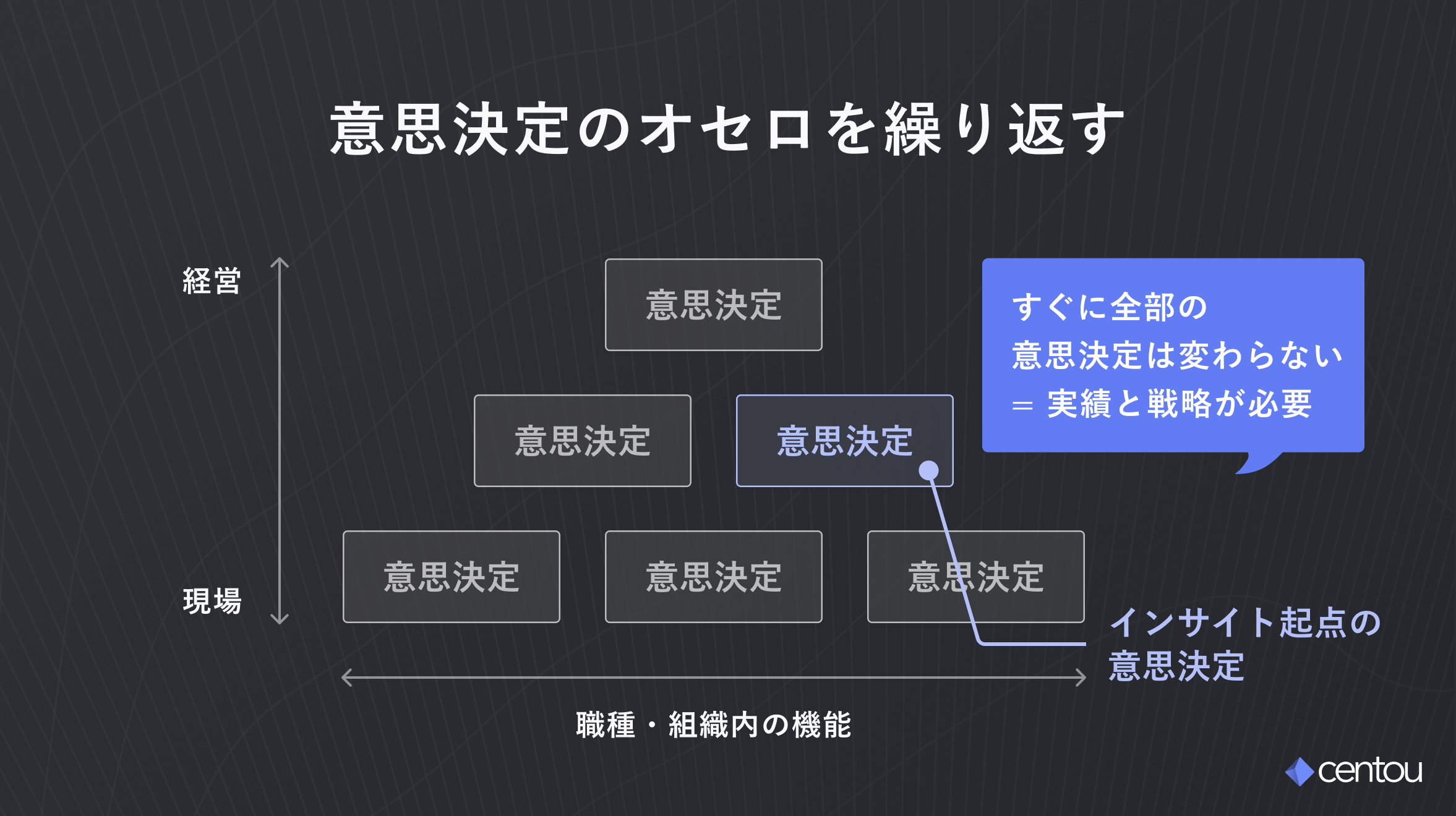
まずは自身のプロジェクトや、自身の所属する最も小さいチームから、インサイトセンターを構築することから始めてみませんか?





